
Bien souvent, lorsqu’un algorithme n’est pas assez performant, nous cherchons à le simplifier et l’optimiser. Aujourd’hui, nous allons voir cela sous un aspect bien particulier, en essayant de tirer plus largement profit du matériel à notre disposition dans nos PC.
Cela fait maintenant plusieurs années que les fréquences des processeurs stagnent. (graphe issu de http://cpudb.stanford.edu/visualize/clock_frequency)
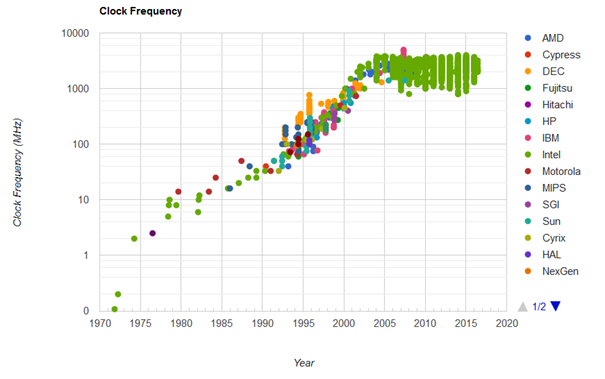
Les progrès se font sur le nombre de cœurs ou dans les extensions capables de traiter plusieurs données en même temps afin de gagner en vitesse.
Algorithme
Pour cet article, nous allons partir sur un exemple simple, la recherche de doublons dans un tableau d’entiers. Ce problème a une complexité en O(n²). Il serait possible de faire baisser cette complexité en triant les éléments, ou encore en utilisant une table de hashage, mais ce n’est pas le sujet sur lequel nous allons nous pencher aujourd’hui.
Implémentation naïve
Pour commencer, nous allons voir comment traiter ce problème de manière naïve, puis tenterons ensuite de reproduire la solution en incluant les améliorations qui nous intéressent. Ainsi, pour chaque élément du tableau, nous devons parcourir tous les autres éléments pour les comparer et signaler la présence d’un doublon à cet endroit, avec l’aide d’un tableau de booléens.
Le code final est disponible ici : https://github.com/vivienmetayer/Hardware_acceleration/tree/master/CPU_GPU_time_comparison
std::vector<bool> detect_duplicates_CPU_simple(std::vector<int>& v) { int size = v.size(); std::vector<bool> duplicates(size, false); for (int i = 0; i < size-1; ++i) { for (int j = i+1; j < size; ++j) { if (v[i] == v[j]) { duplicates[i] = true; duplicates[j] = true; break; } } } return duplicates; }
Nous nous contentons de vérifier la présence dans les éléments qui se situent plus loin dans le tableau, car les doublons sont déjà censés avoir été trouvés pour ceux d’avant. Aussi, nous arrêtons les recherches dès que nous avons trouvé un doublon, les suivants seront détectés par la suite de l’algorithme.
Pour chaque façon de résoudre le problème, nous mesurons le temps avec std::chrono afin de pouvoir comparer les solutions et constater les améliorations.
auto t0 = std::chrono::system_clock::now(); std::vector<bool> duplicates = detect_duplicates_CPU_simple(v); auto t1 = std::chrono::system_clock::now(); std::cout << "base CPU Time : " << std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count() << std::endl;
Avant même d’envisager d’utiliser plusieurs threads, nous pouvons améliorer notre résultat en utilisant quand c’est possible les fonctions de la STL, dans ce cas find, afin de trouver le doublon.
std::vector<bool> detect_duplicates_CPU_std(std::vector<int>& v) { int size = v.size(); std::vector<bool> duplicates(size, false); for (int i = 0; i < size - 1; ++i) { auto it = std::find(v.begin() + i + 1, v.end(), v[i]); if (it != v.end()) { duplicates[i] = true; duplicates[std::distance(v.begin(), it)] = true; } } return duplicates; }
Ces fonctions sont souvent plus optimisées que celles que l’on écrit pour les remplacer. Cela explique le gain de temps par rapport à la première implémentation.
Multi thread
L’implémentation précédente était correcte, mais nous pouvons constater, par exemple dans Visual Studio, que le processeur est utilisé à un très faible pourcentage.
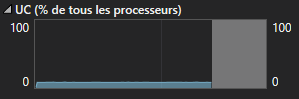
C’est tout à fait normal, un seul cœur fait tout le travail. Si nous voulons améliorer cet aspect, il nous faut répartir le travail en plusieurs threads.
Pour cela, nous utilisons les threads, présents depuis C++11. Nous découpons la totalité de la tâche en plusieurs threads, que nous lançons en même temps. Chaque thread doit connaître son travail et donc la portion du tableau sur laquelle il doit effectuer l’algorithme.

Nous devons faire attention à ne pas dépasser les limites de notre tableau initial dans chaque thread, comme illustré ci-dessus par une case grise.
Chaque thread est responsable de sa valeur dans le tableau.
void detect_duplicates_CPU_thread_std(std::vector<int>& v, int start_index, int end_index, int max_size, std::vector<bool>& duplicates) { for (int i = start_index; i < end_index; ++i) { if (i >= max_size) return; auto it = std::find(v.begin() + i + 1, v.end(), v[i]); if (it != v.end()) { duplicates[i] = true; duplicates[std::distance(v.begin(), it)] = true; } } }
Ils sont appelés tous ensemble et travaillent en parallèle de la manière suivante.
void detect_duplicates_CPU_multithread_std(std::vector<int>& v, std::vector<bool>& duplicates) { int size = v.size(); std::vector<std::thread> threads; for (int i = 0; i < num_threads; ++i) { const int thread_size = ceil(size / num_threads); int start = i * thread_size; int end = start + thread_size; threads.emplace_back(detect_duplicates_CPU_thread_std, std::ref(v), start, end, size, std::ref(duplicates)); } for (auto& t : threads) { if (t.joinable()) { t.join(); } } }
Il est tout à fait possible de demander plus de threads que le nombre indiqué par notre CPU, c’est alors le système d’exploitation qui va gérer les ressources pour nous. D’ailleurs, faire augmenter ce nombre peut régler certains problèmes, comme une quantité de travail pas toujours équilibrée entre les threads, ce qui est le cas de notre problème. En effet, les derniers threads n’auront que quelques valeurs à vérifier, alors que les premiers peuvent parcourir tout le tableau pour rechercher un doublon. L’efficacité va donc diminuer lorsqu’il ne restera que quelques threads qui travaillent sur la partie la plus longue de l’algorithme.
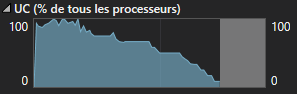

SIMD
En plus de posséder plusieurs cœurs et donc de pouvoir faire plusieurs choses en même temps, les CPU récents possèdent des extensions SIMD (Single Instruction Multiple Data). Elles permettent de lancer une même instruction sur plusieurs données en même temps. Afin de savoir quelles fonctions utiliser, je conseille la doc d’Intel : https://software.intel.com/sites/landingpage/IntrinsicsGuide/
Afin d’améliorer notre détection de doublon, nous allons remplir un vecteur et utiliser une fonction de comparaison sur tous les éléments. Dans cet exemple, AVX2 sera utilisé. Il propose des vecteurs de 256 bits, donc nous pouvons grouper les entiers par huit.
Afin de pouvoir utiliser les extensions, nous devons inclure les fichiers suivants.
#include <xmmintrin.h> #include <immintrin.h>
Il faut faire attention aux bordures de notre tableau, étant donné que l’on charge les données par groupe, nous pouvons accéder à de la mémoire au-delà des limites du tableau. Pour pallier ce problème, nous ajoutons des valeurs qui ne seront jamais recherchées à la fin de notre tableau.
std::vector<bool> detect_duplicates_CPU_SIMD(std::vector<int> &v) { long long size = v.size(); std::vector<int> v2(size + 8, 0); for (int i = 0; i < 8; ++i) { v.push_back(-1); } std::vector<bool> duplicates(size, false); for (int i = 0; i < size-1; ++i) { long long rest = size - i - 1; int num_m256 = ceil(rest / 8.0); // Set element to compare in vector __m256i element = _mm256_set1_epi32(v[i]); for (int j = 0; j < num_m256; ++j) { int index = i + 1 + j * 8; // Load next 8 values __m256i data = _mm256_loadu_epi32(&v[index]); // Compare __m256i t0 = _mm256_cmpeq_epi32(data, element); // If at least one duplicate found if (_mm256_movemask_epi8(t0) != 0) { v2[i] = -1; // load data from v2, do a OR to add the result __m256i data_v2 = _mm256_loadu_epi32(&v2[index]); data_v2 = _mm256_or_si256(data_v2, t0); // Store the result _mm256_storeu_epi32(&v2[index], data_v2); break; } } } // Transform v2 into a bool vector std::transform(v2.begin(), v2.end() - 8, duplicates.begin(), [](const int a) {return a != 0; }); return duplicates; }
On constate que par rapport aux implémentations précédentes, nous allouons de la mémoire pour ne pas lire en dehors du tableau.
Ensuite, nous utilisons les fonctions AVX2 :
- _mm256_set1_epi32 pour remplir un vecteur avec la valeur en cours à comparer
- _mm256_loadu_epi32 fait de même avec un vecteur de 8 valeurs du tableau, le suffixe u est important car il permet de charger de la mémoire non alignée sans problème.
- _mm256_cmpeq_epi32 compare les deux vecteur et place 0xffffffff là où les valeurs sont égales, 0 ailleurs.
- _mm256_movemask_epi8 créer un masque avec les bits de poids fort de chaque élément de 8 bits. Cela permet de vérifier si au moins un élément est non nul.
- _mm256_or_si256 fait un OU sur tous les 256 bits de deux vecteurs en entrée afin d’ajouter des valeurs -1 (qui représentent les doublons trouvés) dans le vecteur de résultats.
- _mm256_storeu_epi32 enregistre le vecteur dans la mémoire à l’emplacement indiqué.
Le fonctionnement est résumé dans le graphe ci-dessous

De la même manière que pour l’implémentation naïve, nous pouvons la aussi effectuer ce calcul sur plusieurs threads avec le code suivant.
void detect_duplicates_CPU_SIMD_thread(std::vector<int>& v, std::vector<int>& v2, int start_index, int end_index, int max_size, std::vector<bool>& duplicates) { for (int i = start_index; i < end_index; ++i) { if (i >= max_size) return; int rest = max_size - i - 1; int num_m256 = ceil(rest / 8.0); // Set element to compare in vector __m256i element = _mm256_set1_epi32(v[i]); for (int j = 0; j < num_m256; ++j) { int index = i + 1 + j * 8; // Load next 8 values __m256i data = _mm256_loadu_epi32(&v[index]); // Compare __m256i t0 = _mm256_cmpeq_epi32(data, element); // If at least one duplicate found if (_mm256_movemask_epi8(t0) != 0) { v2[i] = 1; // load data from v2, do a OR to add the result __m256i data_v2 = _mm256_loadu_epi32(&v2[index]); data_v2 = _mm256_or_si256(data_v2, t0); // Store the result _mm256_storeu_epi32(&v2[index], data_v2); break; } } } } std::vector<bool> detect_duplicates_CPU_SIMD_multithread(std::vector<int>& v) { // Add 8 elements to prevent reading outside vector long long size = v.size(); std::vector<int> v2(size + 8, 0); for (int i = 0; i < 8; ++i) { v.push_back(-1); } std::vector<bool> duplicates(size, false); // launch threads std::vector<std::thread> threads; for (int i = 0; i < num_threads; ++i) { const int thread_size = static_cast<int>(ceil(size / num_threads)); int start = i * thread_size; int end = start + thread_size; threads.emplace_back(detect_duplicates_CPU_SIMD_thread, std::ref(v), std::ref(v2), start, end, size, std::ref(duplicates)); } // join threads for (auto& t : threads) { if (t.joinable()) { t.join(); } } // transform to get a bool array, ignoring the last 8 elements added at the beginning std::transform(v2.begin(), v2.end() - 8, duplicates.begin(), [](const int a) {return a != 0; }); return duplicates; }
Nous pouvons alors comparer le temps pris par les différentes méthodes. Dans mon cas, le gain de temps est conséquent. Nous pouvons maintenant dire que nous utilisons le CPU de manière bien plus efficace qu’au départ.
CUDA
Si nous voulons gagner en performances, nous pouvons aussi nous orienter vers le GPU. Pour cet exemple, j’utiliserai CUDA. Ce code sera donc utilisable uniquement avec une carte NVIDIA. Pour ceux qui n’en disposent pas, il est possible de faire de même avec OpenCL, il faudra juste écrire un peu plus de code.
Une fois CUDA installé et le projet configuré pour l’utiliser, il faut définir un kernel, qui sera la fonction exécutée par le GPU en parallèle. Dans notre cas, nous assignons un thread par valeur du tableau. Chaque kernel devra alors chercher dans la mémoire un doublon.
__global__ void detect_duplicates(const int* in, bool* duplicates, int numElements) { int i = blockDim.x * blockIdx.x + threadIdx.x; if (i >= numElements) return; for (int j = i + 1; j < numElements; ++j) { if (in[i] == in[j]) { duplicates[i] = true; duplicates[j] = true; break; } } }
Afin de pouvoir appeler cette fonction sur le GPU, il faut d’abord allouer de la mémoire pour le tableau d’entiers et celui de résultat avec la fonction cudaMalloc.
cudaError_t err = cudaSuccess; int size = v.size(); std::vector<unsigned char> duplicates_U8(size, 0); std::vector<bool> duplicates(size, false); int* d_in = nullptr; unsigned char* d_out = nullptr; err = cudaMalloc(&d_in, 4 * size); if (err != cudaSuccess) { std::cout << "error allocating d_in array" << std::endl; } err = cudaMalloc(&d_out, size); if (err != cudaSuccess) { std::cout << "error allocating d_out array" << std::endl; }
Ensuite, nous copions les données avec cudaMemcpy, en précisant bien le sens, de Host (le CPU) vers Device (le GPU).
err = cudaMemcpy(d_in, v.data(), size * 4, cudaMemcpyHostToDevice); if (err != cudaSuccess) { std::cout << "error copying d_in array" << std::endl; }
Nous appelons la fonction avec une notation un peu spéciale, en ajoutant le nombre de threads ainsi que le nombre de blocs entre triple chevrons.
int threads_per_block = 32; int num_blocks = (size + threads_per_block - 1) / threads_per_block; auto t0 = std::chrono::system_clock::now(); detect_duplicates_v3 << <dim3(num_blocks, num_blocks), dim3(threads_per_block, threads_per_block) >> > (d_in, d_out, size); cudaDeviceSynchronize(); auto t1 = std::chrono::system_clock::now(); std::cout << "CUDA kernel Time : " << std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count() << std::endl;
Finalement, le résultat est récupéré avec un autre cudaMemcpy, et transformé en vecteur de bool pour conserver le même format que les autres fonctions.
Nous observons avec mon matériel (Ryzen 7 5600X, GTX 1060 6Gb) des temps similaires entre la fonction utilisant SIMD en multithread et le temps passé dans le kernel CUDA.
Conclusion
Nous avons vu qu’il était possible de gagner beaucoup de temps en se penchant sur les possibilités qu’offrent le matériel présent dans nos PC.
Voici quelques résultats en terme de temps en fonction du nombre d’éléments dans le tableau.

Ce gain est à mettre en balance avec le temps de développement et la maintenabilité du programme. Bien évidemment, la première fonction est la plus lente mais aussi la plus simple et rapide à écrire. Elle présente aussi l’avantage d’être très facile à maintenir en raison de sa simplicité.
La première étape si le besoin d’optimisation se fait sentir sera toujours de réfléchir à un moyen de baisser la complexité, en implémentant une solution différente. Si ce n’est pas possible, alors le multi thread sera certainement l’option à considérer en premier lieu, car il suffira de diviser le travail entre tous les cœurs du CPU.
Les solutions impliquant les extensions SIMD et les GPU sont plus complexes à mettre en œuvre, mais permettent d’aller encore plus loin dans l’optimisation. Pour donner un ordre d’idée, voici les différents temps réalisés en fonction du nombre d’éléments dans le tableau. (Rappel : tests effectués sur mon Ryzen 5 3600X avec une GTX 1060 6Go).
Edit : ajout de la RTX 3060Ti
Après avoir fait l’acquisition d’un nouveau GPU, voici le graphe mis à jour. Les performances CUDA sont largement améliorées !


